Into the heart of darkness. And back again.
I just don’t seem to learn, do I?
Don’t touch anything!
The previous story told how I did one last project before I left this company. This project involved customisation (for one customer) of the way data was acquired and processed by two applications. In the past, when I changed these applications, I would always introduce errors. My project manager’s motto was “If it works, don’t touch it!”. As if this application was a house of cards… Unfortunately most of the code didn’t work. I had to change some critical code to implement this customisation.
There be monsters here!
 Why did I get this project? Probably because no one else dared to take on this project. The main part of the coding would be deep in the bowels of the applications, written long ago. It was like a dark, dank, dangerous dungeon nobody dared to enter. There had been some stories about people going in, but they hadn’t been seen again.
Why did I get this project? Probably because no one else dared to take on this project. The main part of the coding would be deep in the bowels of the applications, written long ago. It was like a dark, dank, dangerous dungeon nobody dared to enter. There had been some stories about people going in, but they hadn’t been seen again.
Test yourself!
This feature was intended for one customer. The number one requirement was that for all other customers, the results should be totally compatible with the previous versions of the software. Our customers needed to be able to compare new measurements to their historical data. Hmmm, how could I be sure that my changes didn’t introduce any incompatibilities in the resulting data? This piece of code processed megabytes of data as they came in from the data acquisition hardware. I would never be able to verify its correctness by hand.
Who can verify this data fast enough? The application, of course! If it was fast enough to process the data, it was fast enough to verify the data. I restructured the affected code to look like this:
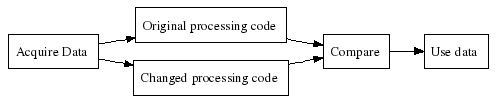
Cleaning the dungeon
At first, “Changed code” was a copy of the original code. As expected, the “Compare” stage indicated that there were no differences between the two streams.
This code was a real mess: it was hard to understand, full of low-level C pointer manipulations, long functions, function names without meaning, 1 or 2-letter variable names… To understand the code, I started to make small changes. After each small change, I would re-run the application with test data to verify that I hadn’t introduced any incompatibilities. If anything was broken, I undid the change.
After a few days of making these small changes, I had transformed the scary dungeon into a light, airy, cosy little room: the code was now simple and easy to understand. It gave the same results as the original disgusting code. No monsters had been seen or harmed during this transformation.
Now I could implement that feature. It was extremely easy and only took me a couple of hours. I used the same technique to verify that my changes were compatible if the feature was not activated.
And what have we learned from this?
This time I had learned something: you should always have tests for your code. On the next major project, we wrote a whole set of tests that exercised the code we were writing. The test called all of our methods with certain test data and print out the results. I looked at the output and see if everything was well. I ran tests every day, so that we discovered errors early. I was the TestRunner.
When I left that project, nobody ran the tests any more. It was too difficult and time-consuming to run the test application and interpret the results. They might run it once in a while if there was a serious bug, but the test was finally forgotten.
And things were back to normal: people were scared to make changes, bugs weren’t caught quickly, more bug reports came in from testers and customers … That’s how it’s supposed to be, isn’t it?